NumPy Internals: Tại Sao Vectorization Quan Trọng
Ngày 2 của hành trình Android-to-AI, và chúng ta sẽ đi thẳng vào phần sâu: NumPy internals.
Nếu bạn đến từ Java hoặc Kotlin như tôi, có lẽ bạn đã dùng NumPy một chút và nghĩ “okay, nó là fast arrays, tôi hiểu rồi.” Nhưng sau khi dành một ngày thực sự tìm hiểu tại sao NumPy nhanh, tôi nhận ra mình đã bỏ lỡ toàn bộ vấn đề. Nó không chỉ về arrays — mà là về một paradigm tính toán hoàn toàn khác.
Để tôi cho bạn thấy ý tôi là gì.
Lời Hứa: Tại Sao Bạn Nên Quan Tâm?
Đây là thỏa thuận: Các operation NumPy có thể nhanh hơn 100-1000 lần so với code Python tương đương. Đó không phải lỗi đánh máy. Khi lần đầu nghe điều này, não Java của tôi nghĩ ngay “chắc là trick JIT compilation nào đó, giống như HotSpot optimizations.”
Không phải. Nó là thứ gì đó thanh lịch hơn — và hiểu được nó sẽ thay đổi cách bạn nghĩ về data processing mãi mãi.
Đến cuối bài này, bạn sẽ hiểu:
- Tại sao
ArrayList<Integer>vànumpy.ndarraylà hai thứ khác nhau hoàn toàn - Làm sao NumPy đạt được tốc độ nhanh hơn 100 lần mà không có magic
- Cái bẫy “views vs copies” sẽ cắn bạn (nó đã cắn tôi rồi)
- Khi nào dùng NumPy vs plain Python
Bắt đầu thôi.
Tại Sao Arrays Không Phải Lists
Java ArrayList: Thực Sự Đang Xảy Ra Điều Gì
Khi bạn viết trong Java:
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 1_000_000; i++) {
list.add(i);
}Đây là những gì thực sự trong memory:
ArrayList object:
├── elementData → Object[] array
│ ├── [0] → Integer object → 0
│ ├── [1] → Integer object → 1
│ ├── [2] → Integer object → 2
│ └── ...Mỗi số nguyên đều:
- Boxed thành
Integerobject (16+ bytes overhead mỗi object) - Lưu trên heap ở vị trí memory ngẫu nhiên
- Tham chiếu qua pointer từ array
Để truy cập list.get(500000), CPU phải:
- Đọc ArrayList object
- Theo pointer đến Object[] array
- Theo pointer tại index 500000 đến Integer object
- Đọc giá trị int thực từ Integer object
Đó là 3 lần dereference pointer và gần như chắc chắn nhiều cache misses vì các Integer objects nằm rải rác trong memory.
NumPy ndarray: Contiguous Memory
Bây giờ nhìn NumPy:
import numpy as np
arr = np.arange(1_000_000, dtype=np.int64)Trong memory:
ndarray object:
├── data → contiguous buffer
│ └── [0|1|2|3|4|5|6|7|8|9|...] (raw bytes, không có pointers)
├── dtype → int64 (8 bytes mỗi element)
├── shape → (1000000,)
└── strides → (8,)Mỗi số nguyên:
- Raw bytes trong một block liền kề — không boxing, không objects
- Liền kề trong memory — truy cập element N+1 chỉ là “cộng 8 bytes vào address”
- Không pointers — data pointer trỏ trực tiếp đến values
Để truy cập arr[500000], CPU:
- Đọc data pointer từ ndarray
- Cộng
500000 * 8vào address - Đọc 8 bytes
Đó là một lần dereference pointer và data thân thiện với cache vì nó liền kề.
Sự Khác Biệt Memory Footprint
Để tôi cho bạn thấy sự khác biệt thực tế:
import sys
import numpy as np
# Python list of integers
python_list = list(range(1_000_000))
print(f"Python list: {sys.getsizeof(python_list) / 1e6:.1f} MB")
# Không tính các integer objects!
# Tổng thực tế khoảng ~28 MB cho 1M integers
# NumPy array
numpy_arr = np.arange(1_000_000, dtype=np.int64)
print(f"NumPy array: {numpy_arr.nbytes / 1e6:.1f} MB")
# Output: 8.0 MB — chính xác 8 bytes × 1M elementsNumPy dùng ít hơn 3.5 lần memory cho cùng data. Nhưng memory rẻ mà, đúng không? Thắng lợi thực sự là cache locality.
CPU hiện đại có nhiều cấp cache (L1, L2, L3). Khi bạn truy cập memory, CPU không fetch chỉ một byte — nó fetch cả một cache line (thường 64 bytes). Với layout liền kề của NumPy, một lần fetch lấy được 8 integers. Với Integer objects rải rác của Java, bạn có thể chỉ lấy được 1.
Đây là lý do NumPy nhanh: nó không chống lại hardware.
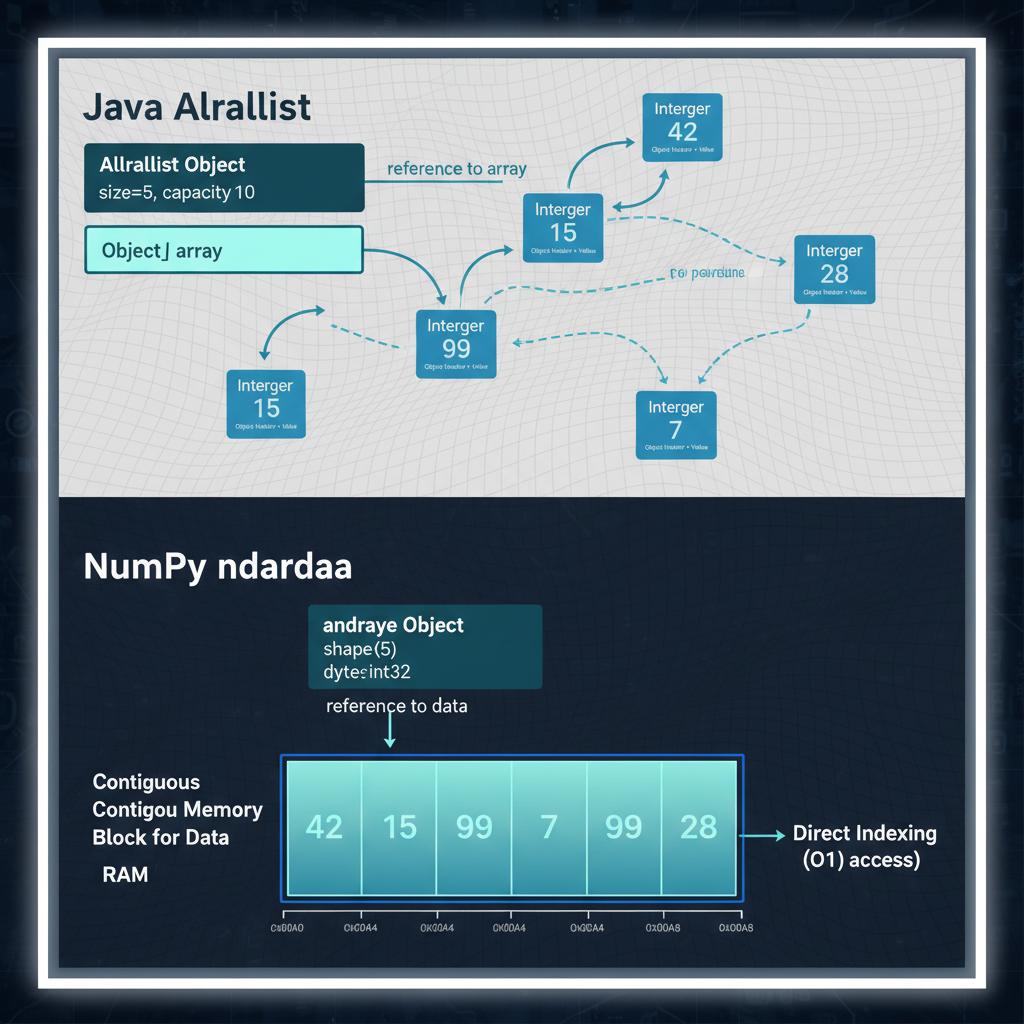 Java ArrayList lưu Integer objects rải rác trong heap với pointer indirection. NumPy lưu raw bytes trong block liền kề — không pointers, không overhead.
Java ArrayList lưu Integer objects rải rác trong heap với pointer indirection. NumPy lưu raw bytes trong block liền kề — không pointers, không overhead.
Memory Layout Deep Dive: C-Order vs Fortran-Order
Đây là điều làm tôi bất ngờ. NumPy arrays có thể được lưu theo hai thứ tự khác nhau:
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr)
# [[1 2 3]
# [4 5 6]]C-order (row-major) — mặc định trong NumPy:
Memory: [1, 2, 3, 4, 5, 6]Row 0 liền kề, rồi row 1.
Fortran-order (column-major) — phổ biến trong scientific computing:
Memory: [1, 4, 2, 5, 3, 6]Column 0 liền kề, rồi column 1.
Tại sao điều này quan trọng? Hiệu quả cache phụ thuộc vào access patterns.
import numpy as np
import time
# Tạo array lớn theo C-order (mặc định)
arr_c = np.random.rand(10000, 10000) # C-order
# Tạo cùng array theo Fortran-order
arr_f = np.asfortranarray(arr_c)
# Sum theo rows (truy cập memory liền kề trong C-order)
start = time.time()
row_sums = arr_c.sum(axis=1)
print(f"C-order, row sum: {time.time() - start:.3f}s")
start = time.time()
row_sums = arr_f.sum(axis=1)
print(f"F-order, row sum: {time.time() - start:.3f}s")
# Sum theo columns (truy cập memory liền kề trong F-order)
start = time.time()
col_sums = arr_c.sum(axis=0)
print(f"C-order, col sum: {time.time() - start:.3f}s")
start = time.time()
col_sums = arr_f.sum(axis=0)
print(f"F-order, col sum: {time.time() - start:.3f}s")Kết quả điển hình:
C-order, row sum: 0.045s
F-order, row sum: 0.095s ← Chậm hơn 2x! Cache misses.
C-order, col sum: 0.089s
F-order, col sum: 0.044s ← Bây giờ F-order thắng.Ví dụ cho Android devs: Giống như RecyclerView được optimize cho vertical scrolling mặc định. Nếu bạn cố scroll ngang mà không config đúng, performance tệ. Memory layout của NumPy cũng nguyên tắc đó — optimize cho access pattern của bạn.
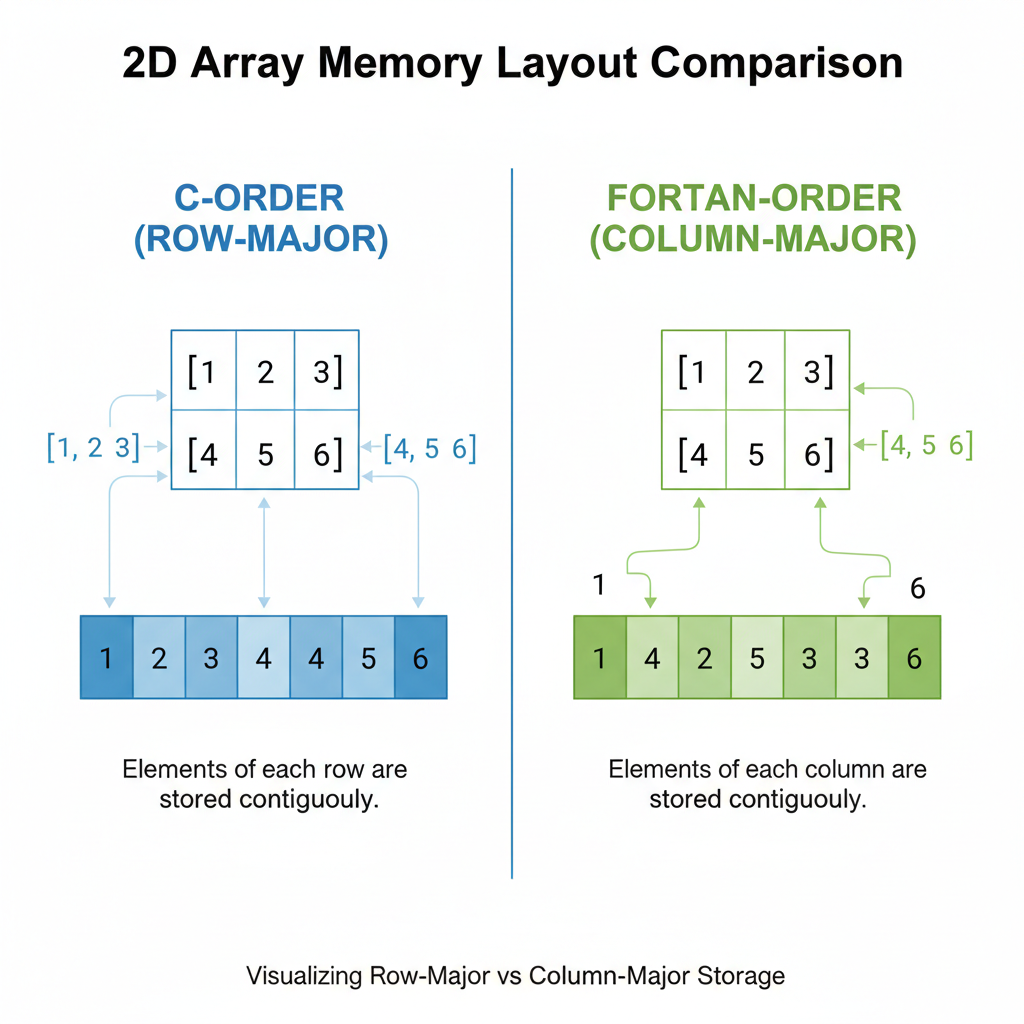 Row-major (C-order) lưu rows liền kề — nhanh cho row operations. Column-major (Fortran-order) lưu columns liền kề — nhanh cho column operations.
Row-major (C-order) lưu rows liền kề — nhanh cho row operations. Column-major (Fortran-order) lưu columns liền kề — nhanh cho column operations.
Hiểu Về Strides
NumPy dùng strides để navigate arrays mà không copy data:
arr = np.arange(12).reshape(3, 4)
print(arr)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(f"Shape: {arr.shape}") # (3, 4)
print(f"Strides: {arr.strides}") # (32, 8)Strides (32, 8) nghĩa là:
- Để di chuyển xuống một row: nhảy 32 bytes (4 elements × 8 bytes)
- Để di chuyển sang phải một column: nhảy 8 bytes (1 element × 8 bytes)
Đây là cách NumPy có thể transpose mà không copy:
arr_T = arr.T
print(f"Transposed strides: {arr_T.strides}") # (8, 32) — chỉ swap!
print(f"Shares memory: {np.shares_memory(arr, arr_T)}") # TrueTranspose chỉ là một “view” khác của cùng data — không copy, operation tức thì. Đây là sự thay đổi paradigm từ Java nơi transpose() sẽ tạo một 2D array hoàn toàn mới.
Vectorization: Bí Mật BLAS/LAPACK
Bây giờ ta đến phép thuật thực sự. Khi bạn viết:
c = a + b # trong đó a và b là NumPy arraysBạn có thể nghĩ Python đang làm gì đó như:
c = np.empty_like(a)
for i in range(len(a)):
c[i] = a[i] + b[i]Sai. Điều thực sự xảy ra:
- NumPy kiểm tra dtypes và shapes
- NumPy gọi một compiled C function mà:
- Sử dụng SIMD instructions (SSE, AVX) để xử lý 4-8 elements mỗi CPU cycle
- Có thể sử dụng nhiều CPU cores (cho arrays lớn)
- Sử dụng BLAS/LAPACK cho linear algebra operations
BLAS (Basic Linear Algebra Subprograms) và LAPACK là Fortran libraries từ những năm 1970-1990 đã được optimize bởi nhiều thế hệ performance engineers. Chúng tốt đến mức ngay cả modern libraries cũng sử dụng chúng.
Ví dụ cho Android devs: Giống như RenderThread của Android offload UI drawing cho GPU. Main thread của bạn nói “draw this list” và RenderThread xử lý execution được optimize với GPU shaders. NumPy nói “cộng các arrays này” và BLAS xử lý execution được optimize với SIMD instructions.
 SIMD (Single Instruction, Multiple Data) xử lý 4-8 elements mỗi CPU cycle. Thay vì cộng từng số một, CPU cộng toàn bộ vectors song song.
SIMD (Single Instruction, Multiple Data) xử lý 4-8 elements mỗi CPU cycle. Thay vì cộng từng số một, CPU cộng toàn bộ vectors song song.
Vấn Đề Python Overhead
Vấn đề với Python loops không phải Python chậm — mà là có overhead mỗi operation:
# Python loop: overhead × N lần
for i in range(1_000_000):
c[i] = a[i] + b[i]
# Mỗi iteration:
# - Python interpret bytecode
# - Fetch a[i] (dict lookup, bounds check)
# - Fetch b[i] (dict lookup, bounds check)
# - Cộng chúng (type check, dispatch to __add__)
# - Store vào c[i] (dict lookup, bounds check)# NumPy: overhead một lần, rồi pure C
c = a + b
# Một lần:
# - Python gọi np.add(a, b)
# - NumPy validate shapes và dtypes
# Rồi trong C (không có Python overhead):
# - SIMD loop xử lý hàng triệu elementsPython overhead có thể là 100 nanoseconds. Làm điều đó 1 triệu lần và bạn đã thêm 100 milliseconds. NumPy trả overhead đó một lần.
Broadcasting Rules: Những Phần Khó
Broadcasting là cách NumPy xử lý operations giữa arrays có shapes khác nhau. Nó mạnh mẽ nhưng có thể gây nhầm lẫn.
Quy Tắc Cơ Bản
Khi operate trên hai arrays, NumPy so sánh shapes từ phải sang trái. Dimensions tương thích nếu:
- Chúng bằng nhau, HOẶC
- Một trong số chúng là 1
# Ví dụ 1: scalar + array (luôn hoạt động)
arr = np.array([1, 2, 3])
result = arr + 10 # 10 broadcasts thành [10, 10, 10]
# Result: [11, 12, 13]
# Ví dụ 2: (3,) + (3, 3) — 1D broadcasts thành rows
arr_1d = np.array([1, 2, 3])
arr_2d = np.array([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
result = arr_1d + arr_2d
# arr_1d trở thành [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
# Result: [[11, 22, 33], [41, 52, 63], [71, 82, 93]]Các Edge Cases Gây Nhầm Lẫn
# Case 1: (3, 1) + (1, 4) → (3, 4)
a = np.array([[1], [2], [3]]) # shape (3, 1)
b = np.array([[10, 20, 30, 40]]) # shape (1, 4)
result = a + b
# a broadcasts thành: [[1, 1, 1, 1],
# [2, 2, 2, 2],
# [3, 3, 3, 3]]
# b broadcasts thành: [[10, 20, 30, 40],
# [10, 20, 30, 40],
# [10, 20, 30, 40]]
print(result.shape) # (3, 4)# Case 2: (3,) + (4,) → ERROR
a = np.array([1, 2, 3]) # shape (3,)
b = np.array([1, 2, 3, 4]) # shape (4,)
# result = a + b # ValueError: shapes not aligned!# Case 3: (3, 4) + (4,) → (3, 4) — trailing dimension matches
a = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]) # shape (3, 4)
b = np.array([10, 20, 30, 40]) # shape (4,)
result = a + b # b broadcasts cho mỗi row
# Result: [[11, 22, 33, 44], ...]Mental model của tôi: Nghĩ về nó như CSS flexbox alignment. Các dimensions stretch để fill shape lớn hơn, nhưng chỉ khi dimension nhỏ hơn là 1 hoặc chúng match chính xác.
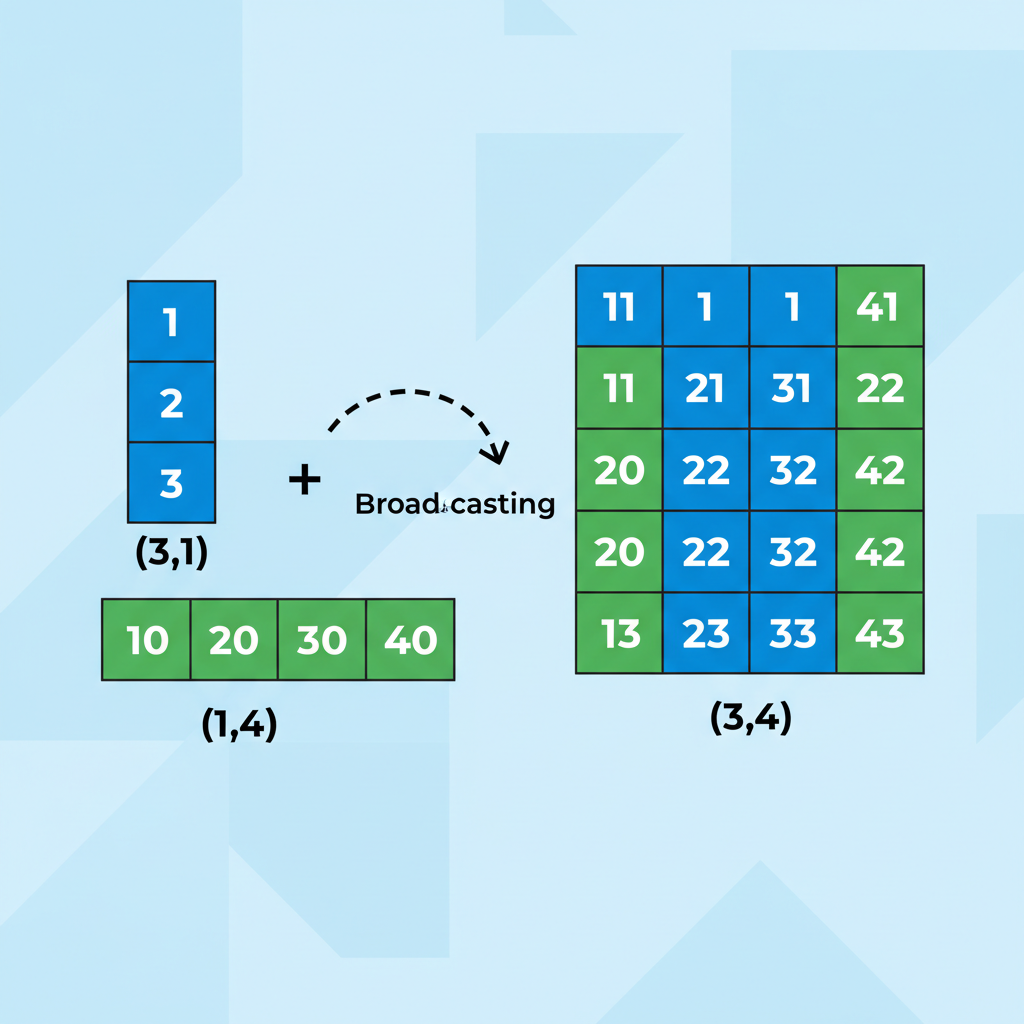 Broadcasting stretch dimensions để match. Array (3,1) mở rộng ngang, array (1,4) mở rộng dọc, tạo ra kết quả (3,4) mà không copy data.
Broadcasting stretch dimensions để match. Array (3,1) mở rộng ngang, array (1,4) mở rộng dọc, tạo ra kết quả (3,4) mà không copy data.
Views vs Copies: Những Bugs Tinh Vi
Đây là nơi tôi bị cắn nặng. Để tôi cho bạn thấy:
arr = np.array([1, 2, 3, 4, 5])
# Điều này tạo VIEW (shares memory)
slice_view = arr[1:4]
slice_view[0] = 999
print(arr) # [1, 999, 3, 4, 5] — ORIGINAL ĐÃ THAY ĐỔI!Đến từ Java, nơi Arrays.copyOfRange() luôn tạo array mới, điều này rất bất an. Trong NumPy, slicing tạo view — một ndarray object mới trỏ đến cùng underlying data.
Khi Nào Là View vs Copy
Views (shared memory):
- Basic slicing:
arr[1:4],arr[::2],arr[:, 0] - Transpose:
arr.T - Reshape (khi có thể):
arr.reshape(3, 4) - Ravel (khi contiguous):
arr.ravel()
Copies (new memory):
- Fancy indexing:
arr[[1, 3, 4]],arr[arr > 2] - Explicit copy:
arr.copy() - Hầu hết operations:
arr + 1,np.sin(arr),arr * 2
Cách Kiểm Tra
arr = np.arange(10)
slice_a = arr[2:5] # View
slice_b = arr[[2, 3, 4]] # Copy
print(np.shares_memory(arr, slice_a)) # True
print(np.shares_memory(arr, slice_b)) # FalsePattern An Toàn
Nếu bạn đến từ Java và muốn behavior dự đoán được, luôn copy khi nghi ngờ:
# Safe pattern: explicit copy
slice_safe = arr[1:4].copy()
slice_safe[0] = 999
print(arr) # Original không đổiVí dụ cho Android devs: Giống như MutableLiveData vs LiveData. Nếu bạn expose MutableLiveData cho View layer, họ có thể modify state của bạn bất ngờ. NumPy views có cùng nguy hiểm — mutations lan truyền đến original array. Dùng .copy() giống như bạn dùng .asLiveData() để ngăn chặn mutations không mong muốn.
Benchmark: 4 Cách Nhân Matrices
Hãy xem sự khác biệt performance trong thực tế. Ta sẽ nhân hai matrices 1000x1000:
import numpy as np
import time
n = 1000
A = np.random.rand(n, n)
B = np.random.rand(n, n)
# Method 1: Python nested loops (chậm nhất)
def python_matmul(A, B):
n = len(A)
C = [[0.0] * n for _ in range(n)]
for i in range(n):
for j in range(n):
for k in range(n):
C[i][j] += A[i][k] * B[k][j]
return C
# Method 2: NumPy với Python loop (vẫn chậm)
def numpy_loop_matmul(A, B):
n = A.shape[0]
C = np.zeros((n, n))
for i in range(n):
for j in range(n):
C[i, j] = np.dot(A[i, :], B[:, j])
return C
# Method 3: NumPy @ operator (nhanh)
def numpy_matmul(A, B):
return A @ B
# Method 4: np.einsum (linh hoạt và nhanh)
def einsum_matmul(A, B):
return np.einsum('ik,kj->ij', A, B)
# Timing (chỉ làm subset cho method 1 & 2)
print("Method 1 (Python loops, 100x100):")
A_small = np.random.rand(100, 100).tolist()
B_small = np.random.rand(100, 100).tolist()
start = time.time()
_ = python_matmul(A_small, B_small)
print(f" Time: {time.time() - start:.3f}s")
print("\nMethod 2 (NumPy with loop, 100x100):")
A_small = np.random.rand(100, 100)
B_small = np.random.rand(100, 100)
start = time.time()
_ = numpy_loop_matmul(A_small, B_small)
print(f" Time: {time.time() - start:.3f}s")
print("\nMethod 3 (NumPy @, 1000x1000):")
start = time.time()
_ = A @ B
print(f" Time: {time.time() - start:.3f}s")
print("\nMethod 4 (einsum, 1000x1000):")
start = time.time()
_ = np.einsum('ik,kj->ij', A, B)
print(f" Time: {time.time() - start:.3f}s")Kết quả điển hình trên MacBook của tôi:
Method 1 (Python loops, 100x100):
Time: 1.247s
Method 2 (NumPy with loop, 100x100):
Time: 0.089s
Method 3 (NumPy @, 1000x1000):
Time: 0.021s
Method 4 (einsum, 1000x1000):
Time: 0.058sMethod 1 mất 1.2 giây cho matrices 100×100. Ngoại suy đến 1000×1000 (gấp 1000 lần công việc): đó là ~1200 giây = 20 phút.
Method 3 làm 1000×1000 trong 0.02 giây.
Đó là tăng tốc 60,000 lần. Không phải lỗi đánh máy.
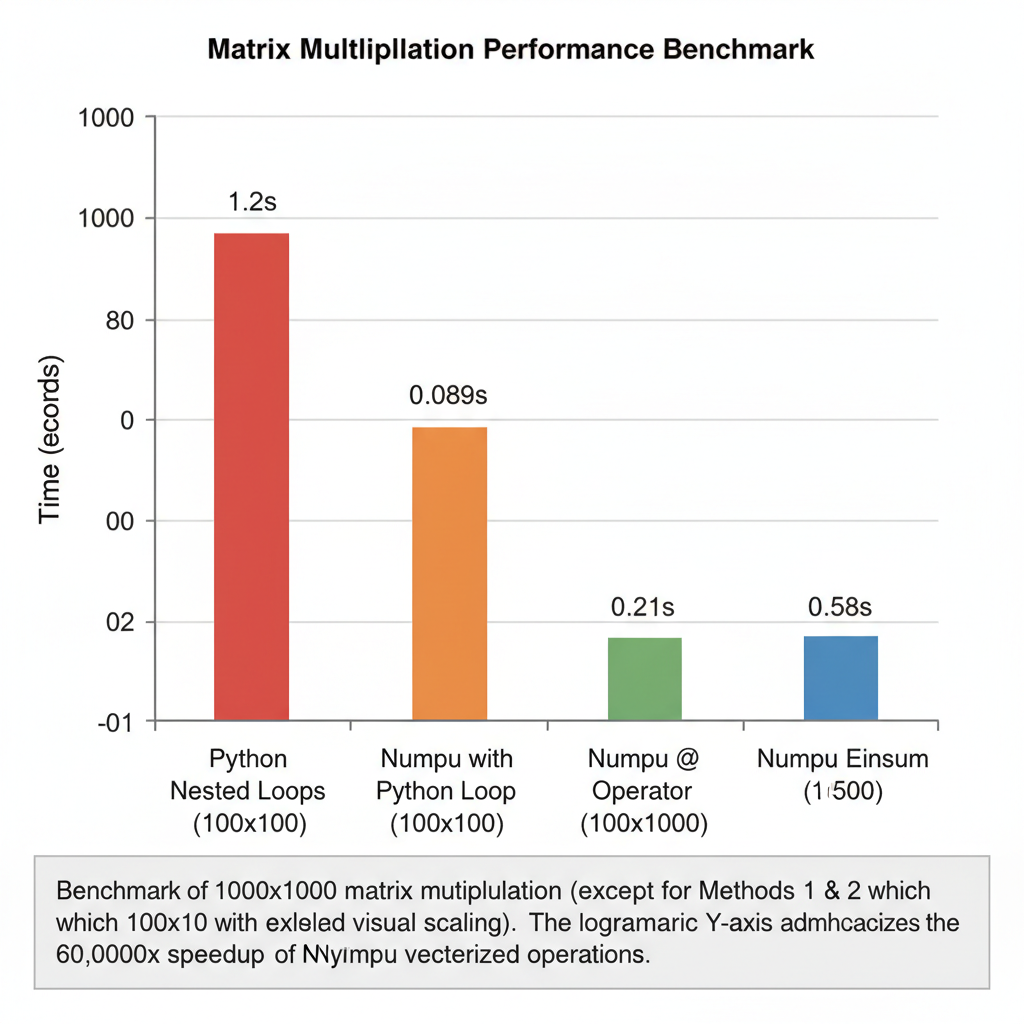 Python loops: 20 phút. NumPy @: 0.02 giây. Sự khác biệt không phải tăng dần — mà là biến đổi hoàn toàn.
Python loops: 20 phút. NumPy @: 0.02 giây. Sự khác biệt không phải tăng dần — mà là biến đổi hoàn toàn.
Sự Thay Đổi Mental Model
Đây là paradigm change mà tôi ước ai đó đã nói với tôi ngày đầu tiên:
Tư duy cũ (imperative, từ Java):
“Loop qua mỗi element và apply operation.”
Tư duy mới (declarative, NumPy):
“Mô tả transformation bạn muốn trên toàn bộ array.”
Đó là sự thay đổi giống như đi từ:
// Imperative Java
List<Integer> doubled = new ArrayList<>();
for (int x : numbers) {
doubled.add(x * 2);
}Sang:
# Declarative NumPy
doubled = numbers * 2 # Không có loop trong code của bạnHoặc nghĩ về SQL: bạn không viết for each row in table: if row.age > 21: add to results. Bạn viết SELECT * FROM users WHERE age > 21. Bạn mô tả kết quả, không phải các bước.
NumPy (và sau đó pandas) hoạt động cùng cách. Ngừng nghĩ “iterate through elements.” Bắt đầu nghĩ “describe the transformation.”
Những Takeaways Thực Tế
Khi Nào Dùng NumPy vs Plain Python
Dùng NumPy khi:
- Làm việc với numerical data (arrays of numbers)
- Làm mathematical operations trên collections
- Performance quan trọng (data > 1000 elements)
- Bạn cần linear algebra operations
- Processing images, signals, hoặc scientific data
Dùng plain Python khi:
- Làm việc với mixed types hoặc complex objects
- Data tự nhiên là nested/hierarchical (dùng dicts/classes)
- Bạn đang làm string processing (dùng built-in str methods)
- Operations về bản chất là sequential với dependencies
Quy Tắc Duy Nhất
Không bao giờ loop qua NumPy array elements trong Python.
Nếu bạn thấy mình viết for i in range(len(arr)), dừng lại. Hầu như luôn có cách vectorized.
# XẤU: Python loop
result = []
for x in arr:
if x > threshold:
result.append(x * 2)
# TỐT: Vectorized
mask = arr > threshold
result = arr[mask] * 2Quick Reference: Common Operations
| Java/Python Loop | NumPy Vectorized |
|---|---|
for x in arr: total += x | arr.sum() |
max_val = max(arr) | arr.max() |
for i, x in enumerate(arr): arr[i] = x * 2 | arr *= 2 |
for i in range(len(a)): c[i] = a[i] + b[i] | c = a + b |
[x for x in arr if x > 0] | arr[arr > 0] |
[f(x) for x in arr] | np.vectorize(f)(arr) hoặc tốt hơn: tìm NumPy function |
Tiếp Theo
Ngày mai ta tackle pandas — nơi cùng vectorization principles áp dụng, nhưng cho tabular data với labels, missing values, và mixed types. Nếu NumPy là nền tảng, pandas là tòa nhà.
Mental model: “Think in Transformations, Not Loops” sẽ mang trực tiếp sang. Nhưng pandas thêm complexity: index alignment, cái đáng sợ SettingWithCopyWarning, và câu hỏi khi nào dùng pandas vs khi nào nó trở thành bottleneck.
Đến từ thế giới nơi Room/SQLite xử lý relational data needs của ta, pandas sẽ cảm thấy vừa quen thuộc (nó giống SQL) vừa xa lạ (nó mutable và đầy gotchas).
Hẹn gặp bạn ở Ngày 3.
Resources để đào sâu:
- NumPy Internals Documentation
- From Python to NumPy by Nicolas P. Rougier
- NumPy Broadcasting